
STEP 1: PREVIEW THE BEST DATE RECORD OF YOUR SITE ON ARCHIVE.ORG BELOW
NOTE: ARCHIVE.ORG HAS OLD, OVERLOADED SERVERS SO PLEASE BE PATIENT
HOW TO RESTORE YOUR WHOLE SITE FROM ARCHIVE.ORG FOR $15 TODAY?
If you have ‘lost’ your website from a while ago and now you want to get it back, here is what you need to know about achieving that:
#1: Do you own the domain now?
A domain is not your website. A domain is just the ‘street address’ on the Web of where your website lives e.g. like google.com, facebook.com etc
A website however is the actual text, images and pages that then make up your website content, which sits on a domain.
If you have lost ownership of the domain that your website was on, you will either have to:
[a] negotiate with the current owner to buy it back (domain registrars like Namecheap and Godaddy offer this service but the fees are usually pretty steep and a direct approach is probably more likely to work), or
[b] buy a new similar domain e.g. if the domain/site that you want to get back is tedsguitarshop.com but that is currently owned by someone else and they ain’t selling, think about domains like:
– tedsguitarshop.pro
– tedsguitarshop.club
– tedsguitarshop.net
– tedsguitarshop.co
– tedsguitarshop.online
– tedsguitarshop.us
– tedsguitarshop.live
or one of hundreds of other domain extensions now available.
#2: How do you get your old site files from archive.org?
Archive.org is an underfunded nonprofit trying to store most of the Web in a very, very basic form.
In general, site records from the past at archive.org have missing pages, missing images, broken links and wonky layouts.
However, most of the text and images are normally intact – check all the date records for best result! – and these can be used to restore the site.
BUT extracting all your files from archive.org’s Wayback Machine is very difficult without a tool like Wayback Rebuilder (you’re here – yay!).
So if you only want to extract the files for 1 site, you will need to:
[a] CHOOSE the Single Site Download option here – you can download any or all date records for 1 URL for THREE DAYS for just $15 – it’s a 3 day pass deal:
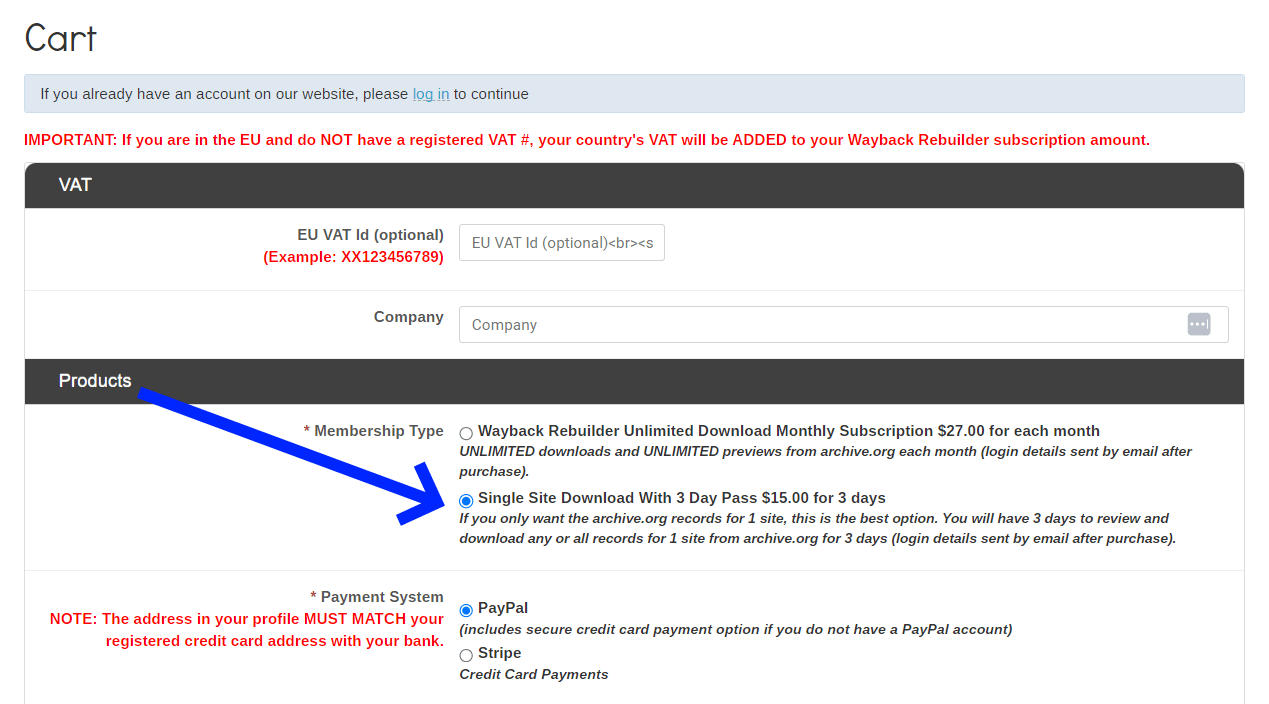
HOWEVER, if you want to download UNLIMITED site records and have UNLIMITED previews each month with our Wayback Rebuilder toolset, then it’s a paltry $27 a month if you want to keep using it, then,
[b] extract the files you want from archive.org for your site rebuild.
#3: How do you get the site looking good again, such as in WordPress?
This is a little more involved, simply no way around that.
You will need to:
[a] get a hosting account with a quality host like WPX.net (they specialize in WordPress).
[b] then point your domain at your domain registrar (e.g. Namecheap, Name.com) to your hosting account, using the host’s nameservers for your account there.
[c] then install an empty WordPress site with your hosting account.
Now for the harder part.
Archive.org only stores files in HTML format, which is NOT WordPress.
So you will now need to choose a layout that you like in WordPress (assuming you’re using that), page builders like Elementor (free version is pretty good) can help a lot with this and they have loads of well-designed templates included to speed up the process.
Once you have a layout that you’re happy with, you can either use a free HTML>WP plugin like this one and depending on the results you achieve, that may be all you need to do (check every page for missing images, broken links or anything else that didn’t work exactly right).
OR
You OR a freelancer you hire on Upwork.com or Fiverr.com needs to add back the text and images and links to each page on the new site, one page at a time, doing it manually.
That option may sound horrible but this work only needs to be done ONCE, assuming you don’t let the site go again in the future without keeping a backup with a tool like Updraft (if using WordPress).
You can also read about other HTML>WP conversion options in this article here.
If you get stuck with anything here, please email us via support(at)waybackrebuilder.com OR use the Live Chat box
in the bottom right of your screen and we will respond ASAP.
© 2024 Kyle Technologies Ltd